此文写于2016年6月12日,一切都在快速变化,欢迎指正!
Docker生态系统
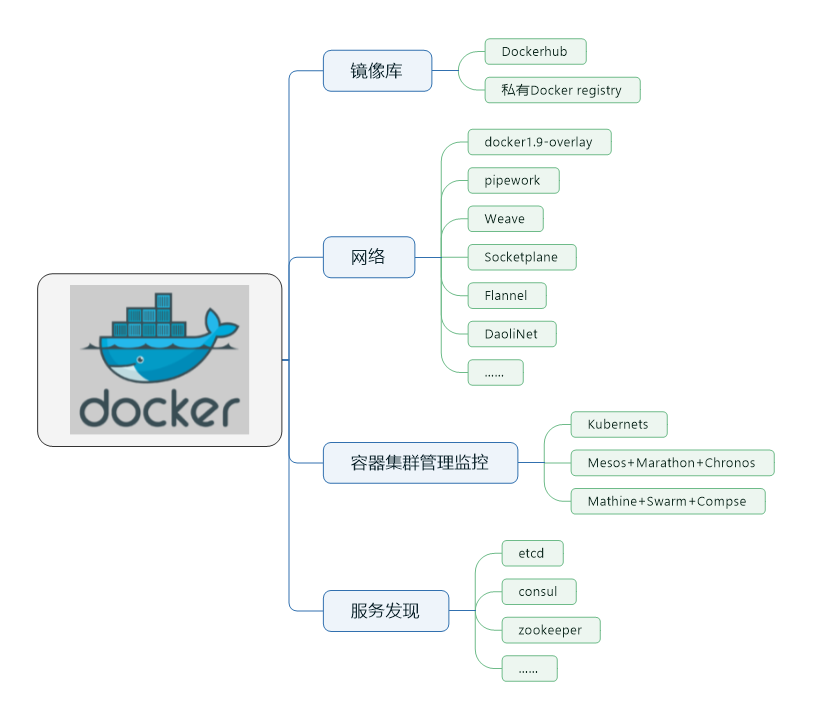
Docker简介Docker是什么? Docker是以docker容器为资源分割和调度的基本单位,封装软件的运行时环境.用于快速构建,发布,运行分布式应用的平台。Docker的运行时容器的本质是进程.在linux中,通过namespace进行资源隔离,cgroups进行资源限制,使docker容器看上去像是一个运行在宿主机中的虚拟机.
docker引擎的简介我们通常说的Docker是指Docker Engine
 Docker容器与虚拟机的根本区别在于,docker容器和宿主机共用linux操作系统内核,不会在宿主机上再次建立OS,轻量级.容器采用分层的机制。如:最底层可能是一个linux发行版,如ubuntu.上面加上JDK层.JDK层之上可以安装tomcat等各种java应用层我们通常所说的docker是指docker引擎.本文主要介绍docker引擎周边的生态系统,关于docker引擎的详细介绍可以参考《docker-软件工程中的集装箱技术》.笔者认为Docker四大特性Docker容器的秒级启动Docker容器实现了应用环境的标准化Docker与mesos.k8s的结合,提供了云服务能力.Docker的高资源利用率(与虚拟机相比) 以上的这些特性,使企业级的微服务架构的实现,提供了真实的具有实践性的可能.
Docker容器与虚拟机的根本区别在于,docker容器和宿主机共用linux操作系统内核,不会在宿主机上再次建立OS,轻量级.容器采用分层的机制。如:最底层可能是一个linux发行版,如ubuntu.上面加上JDK层.JDK层之上可以安装tomcat等各种java应用层我们通常所说的docker是指docker引擎.本文主要介绍docker引擎周边的生态系统,关于docker引擎的详细介绍可以参考《docker-软件工程中的集装箱技术》.笔者认为Docker四大特性Docker容器的秒级启动Docker容器实现了应用环境的标准化Docker与mesos.k8s的结合,提供了云服务能力.Docker的高资源利用率(与虚拟机相比) 以上的这些特性,使企业级的微服务架构的实现,提供了真实的具有实践性的可能.Docker及其生态系统为软件行业带来了什么变化?持续部署与集成.Docker封装了软件的运行时环境,消除了线上与线下的差异,保障了应用在开发,测试,生产运行整个生命周期的一致性.结合jenkins等持续集成软件使用,实现了code(代码)到image(镜像)的快速集成,大大的简化了持续集成,测试,软件发布的过程.环境标准化与版本控制.我们经常使用git,svn,cvs等版本控制工具实现代码级别的版本控制.那有没有想过有一天,可以实现对应用运行时环境进行版本控制呢?docker帮我们实现了,应用myapp的1.0版本使用JDK6(myapp-docker-1.0),应用的2.0版本使用JDK8(myapp-docker-2.0).全部封装到docker镜像里面.上线过程中,2.0版本出现问题怎么办,快速回退1.0版本.因为回退过程,不需要1.0应用环境的重新配置,只是1.0应用版本的容器启动,秒级实现.笔者做个展望:docker镜像将成为未来软件交付的唯一标准!应用服务能力的伸缩性.举个假设的例子,淘宝对于应用服务的能力要求,”双11″期间肯定远远高于日常.docker结合k8s,mesos之类的资源管理及服务编排系统,结合负载均衡服务,可以实现应用规模的快速扩缩.”双11″启动5000个容器,日常启动2000个容器来满足业务的需求.资源的利用率提高上面的淘宝的例子,就避免了服务器资源的浪费,在闲时将服务器资源释放出来.笔者在一台8G,8核心的PC机上,启动了20个ubuntu容器(还可以更多),你可以在这样的一台PC上启动20个虚拟机么?答案显然是否定的.Docker镜像库DockerHub Docker 官方维护了一个公共仓库 Docker Hub,其中已经包括了超过 15,000 的镜像。大部分需求,都可以通过在 Docker Hub 中直接下载镜像来实现。
Docker registry 私有仓库 Registry 作为 Docker 的核心组件之一负责镜像内容的存储与分发,是企业搭建私有docker镜像仓库的解决方案.
Docker Registry目前分为V1和V2两个版本.V2版本相比V1版本有如下几方面的改进:
V1版本push layer操作只判断id,不判断layer的内容.由于镜像内容与id无关,所以重新build之后id变化,内容没变的layer将会重复提交.造成存储资源的浪费.V2采用哈希值方式,被称为 digest 是一个和镜像内容相关的字符串,相同的内容会生成相同的 digest。所以是镜像layer判断是内容相关的.提供了鉴权管理和权限控制V1 registry 中镜像的每个layer 都包含一个json文件包含了父亲 layer 的信息.因此当我们 pull 镜像时需要串行下载,下载完一个 layer 后才知道下一个 layer 的 id 是多少再去下载.
新版 registry 在 image 的 manifest 中包含了所有 layer 的信息,客户端可以并行下载所有的 layer 推荐您看:《Docker registry V2私有仓库搭建》
服务发现机制和全局配置存储 为什么需要服务发现?
当我们部署少量docker容器的时候,我们可以去指定容器的映射端口.但是我们启动大规模的容器集群的时候,我们希望容器的对外服务端口是随机分配的,并且同一台主机内不能发生端口冲突(服务编排及资源管理的系统可以帮我们完成端口的随机分配,这个不是这里要说的事情).
端口随机的分配实现了,那么用户该如何才能知道,这个随机的端口是什么?哪个ip,哪个端口对应哪个服务?这就需要服务发现组件来实现!
基于上述的需求,服务发现的组件应该具备如下基本功能
提供全局的分布式容器信息存储,即键值对的存储工作。提供http的API来get or set值.即:提供注册和查询
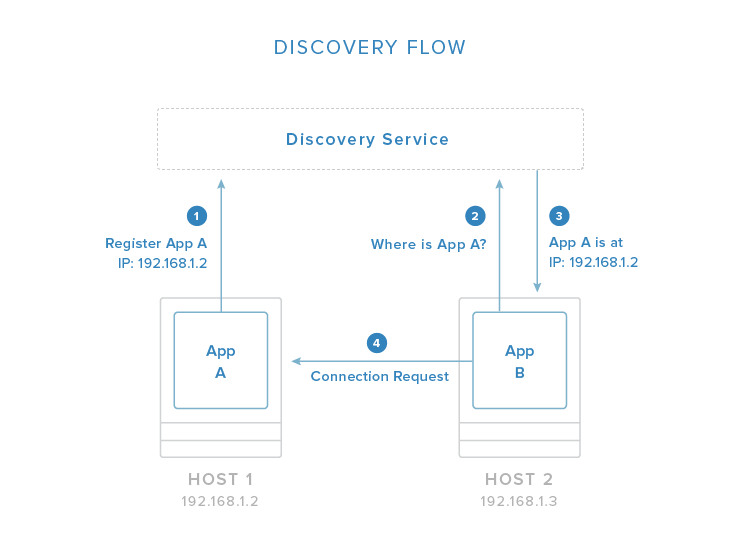
常用的服务发现工具consul: 服务发现/全局的分布式key-value存储。自带DNS查询服务,可以跨数据中心。提供节点的健康检查,可以实现动态的consul节点增减.docker官方的用例推荐!etcd: 服务发现/全局的分布式key-value存储.静态的服务发现,如果实现动态的新增etcd节点,需要依赖第三方组件。zookeeper: 服务发现/全局的分布式key-value存储.使用场景广泛,java编写,资源需求大,比起前两者更加臃肿!Docker 网络 Docker 1.9发布之前,网络的问题一直是困扰docker爱好者的主要问题.实现的复杂度较高,这一切都在发布docker1.9的overlay网络之后得到改善.
docker 1.9之前提供了两种容器之间的网络连接方式
通过docker容器映射端口到宿主机,即暴露端口到宿主机.举例:容器A映射8080到宿主机xx.xx.xx.xx的80端口,其他的容器想访问容器A的端口,就访问xx.xx.xx.xx:80。通过link的方式,连接容器网络.这种方式只适合,单个宿主机之内,无法跨宿主机实现容器之间的互访! 砸一看,似乎有这两种方式就够了.虽然采用第二种无法跨主机,但是第一种还算ok吧?如果一个服务暴露出来很多的端口怎么办?都对外映射么?那样就会造成端口管理上的灾难!
这显然是不行的,这时很多的工具出现了,来做SDN(软件定义网络)网络.容器之间的互访网络.比较有名气的有:
fannel–overlayweave–overlaypipework 但是,docker1.9发布之后,这些Docker网络工具的存在意义逐渐弱化(虽然这些软件还是有一些自己的特点)。docker官方实现了自己的跨主机容器网络方案。
实现方式,请看我的另外两篇
《基于consul的Docker-overlay跨多宿主机容器网络》
《基于etcd的Docker-overlay跨多宿主机容器网络》
容器管理与编排
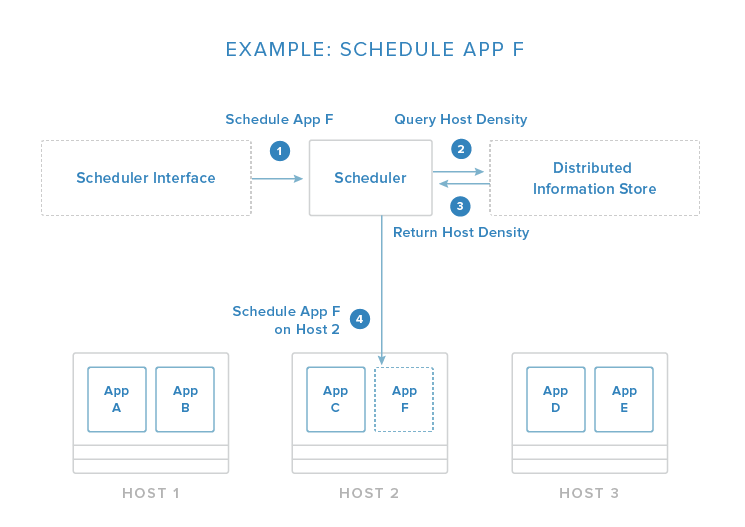
容器编排和管理系统主要解决以下几个问题:
我们需要工具来实现大规模容器分业务分组分服务管理.我们需要指定容器去哪些主机上启动部署容器依赖按照什么顺序启动?做成自动化的自动化的实时扩展或减少分组容器的数量根据集群和节点的资源使用率调度容器的启动位置分组容器对外服务的负载均衡容器及集群的监控告警产品应用支持,如大数据的docker化…… 目前容器编排与管理的系统主要是三个:
mesos + marathon,mesos的本质是一个基于资源的调度管理系统,可以实现docker容器的基于资源的细粒度的容器调度.marathon用来运行长服务,实现健康检查与容器依赖启动,扩展与缩放.在大型的容器集群管理上,有更稳定的表现.
推荐一篇介绍mesos的文章:《煮饺子与mesos之间妙不可言的关系》kubernets是谷歌开发的容器编排管理系统.使用Golang开发,具有轻量化、模块化、便携以及可扩展的特点。它提出了一系列诸如:Pods,Replication Controllers,Labels,Services之类的概念,所以学习的曲线也相对陡峭.Kubernetes的性能要比Swarm差,是因为它拥有更加复杂的架构;性能比Mesos差,是因为它结构层次更深;docker + swarm + compose,docker原生的容器管理系统,简单易用,学习的曲线低,和docker兼容度高,但是实际用于生产环境的案例不多。参考https://www.digitalocean.com/community/tutorials/the-docker-ecosystem-an-introduction-to-common-components 转载请注明:字母哥博客 » docker生态系统综述
煮饺子与mesos之间妙不可言的关系 基于etcd服务发现的overlay跨多宿主机容器网络