5月13日-15日,由全球最大中文IT社区CSDN主办的“2016中国云计算技术大会”(Cloud Computing Technology Conference 2016,简称CCTC 2016)在北京新云南皇冠假日酒店隆重举行,这也是本年度中国云计算技术领域规模最大、海内外云计算技术领袖齐聚、专业价值最高的一场云计算技术顶级盛宴。本次大会以“技术与应用、趋势与实践”为主题,聚焦最纯粹的技术干货分享,和最接地气的深度行业案例实践,汇聚国内外顶尖技术专家,共论最新的云计算技术实践与发展趋势。
大会第二天,在大数据核心技术与应用实战峰会下午场,由来自平安科技、万达金融、青云QingCloud、腾讯、阿里云、Hulu的六位专家继续与大家带来在他们企业内的大数据核心技术与实践。
平安科技高级研究员夏磊豪:两朵云与金融阿法狗 平安科技高级研究员夏磊豪带来的分享是《两朵云与金融阿法狗 》。他从“阿法狗”带来的启示和人工智能进军金融界为切入点展开了此次分享,他认为,部署金融大数据需要将大数据与深度学习和异构计算进行结合。分享之初,他详解了深度学习、异构计算体系原理与应用。夏磊豪向在场听众解释了基于卷积神经网络的深度学习技术,该技术利用图像的空间联系是局部的,使每个神经元只感受局部的图像区域,然后在更高层中,将这些感受不同局部的神经元综合起来就可以得到全局的信息。
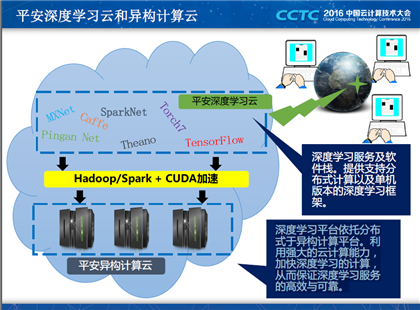
他向在场的听众分别介绍了平安深度学习云和异构计算云:
平安深度学习云:深度学习服务及软件栈。提供支持分布式计算以及单机版本的深度学习框架;
平安异构计算云:深度学习平台依托分布式于异构计算平台。利用强大的云计算能力,加快深度学习的计算,从而保证深度学习服务的高效与可靠。
接下来他谈到了深度学习在金融场景中的应用。推荐方面,基于深度学习的推荐优化算法利用深度学习SDAE(栈化解噪音自动编码器)提取高鲁棒的判定特征,得到高质量的清洗数据,接着得到ITEM/USER矩阵完成精准推荐;风险控制方面,借助人工神经网络模型,将金融客户的交易量、交易类型、交易频率等数据提取为特征向量,输入模型进行欺诈风险评估;智能问答方面:深度学习应用于自动问答与NLP技术,在不同的分类数据集上评估CNN模型,主要基于语义分析和话题分类任务;社交大数据与LBS服务方面:通过活跃用户和非活跃用户的识别提取它在社交网络上涉及金融话题的数据,然后经过深度学习的平台来学习出一些结果,从而产生对用户价值的理解,同时也可以对其他金融业务做一些指导。LBS服务是平安正在尝试的方向,每个人日常的生活中会面对很多的场景,比如像医疗机构、汽修、教育、商城等等,而平安在方方面面有布局的,比如像医疗机构上,平安有万家诊所。很多产品可以成为用户数据的入口,从而为平安提供可供分析的数据。 
平安科技高级研究员 夏磊豪
最后,他对在场观众对获取社交数据方面的问题做了精彩的回答,他提到平安有数据入口,另外也跟一些其他的社交媒体合作获取一些数据。
万达金融李呈祥:Apache Flink: Stream engine beyond Batch 来自万达金融的李呈祥带来的分享是《Apache Flink: Stream engine beyond Batch》。他主要从批处理和流处理、Flink 流处理的核心特性和Flink高级特性三个方面展开了此次分享。分享之处,他谈到所有计算框架最终存在的目的是为了进行数据处理。目前大数据平台处理的数据大概分两类,第一类称为有限的数据集,特点是数据已经存在的,而且一般只有存储的不会丢失。第二类是无限的数据流,它的特点是动态流入的,无穷无尽。所以批处理系统目标是处理有限的数据集,流系统是为了处理无限的数据流。 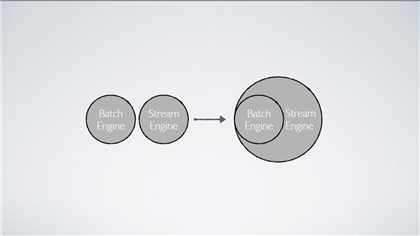
对于批处理执行引擎是否只能够处理有限数据集,而流处理是否只能处理无限的数据流这个问题,他认为答案是否定的,并结合Spark streaming和Flink两种处理引擎的处理方式给出解释。
他认为一个真正的可以大规模应用的流处理系统其中的一个核心特性就是正确性,在批处理中我们从未考虑过正确性,但是在流处理中,必须要考虑这一点。 
万达金融 李呈祥
Flink 最大的特点就是把所有任务当成流来处理,同时Flink 可以支持本地的快速迭代,以及一些环形的迭代任务,并且 Flink 可以定制化内存管理。 Flink与 Spark 相对比,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因,就框架本身与应用场景来说,Flink 更相似与 Storm。
青云QingCloud系统工程师周小四:青云QingCloud大数据云平台基础架构实践 来自青云QingCloud系统工程师周小四给大家带来的分享是《青云QingCloud大数据云平台基础架构实践》。他的的分享主要包括:云计算与大数据、系统架构、挑战三个部分。演讲之初,他提到大数据解决方案最大、最重要的决定是平台的选择,因此平台的能力能满足实际需求的平台才是好平台。谈到云计算带来的好处,他认为主要有三点:弹性、敏捷、灵活。弹性是指即可横向伸缩,又可纵向伸缩,从而为处理大数据减少了成本;敏捷意思是要快,要有快速处理能力;灵活是指各个大数据组件之间可以任意组合,只要它们在软件层面,就应该可以兼容可以组合,并且能够将任意切换下面的存储、引擎。
在大数据技术平台的系统架构,数据的生命周期分为数据采集存储、数据分析以及最后的数据展现三部分。 
青云QingCloud系统工程师 周小四
演讲中,他向在场的听众介绍了云上的SQL实践:HashData 数据仓库,该数据仓库是酷克数据在青云QingCloud 上面提供的SQL-on-Cloud解决方案,是一个高性能、 完全托管的PB级云端数据仓库;源于PostgreSQL 和Greenplum Database, HashData数据仓库让用户能够利用标准SQL客户端和BI工具轻松分析海量数据。
演讲最后,他还分享了大数据上云所存在的挑战,主要包括稳定性、性能(网络 IO 和硬盘 IO )和迁移(Within cloud/Between cloud / on-premise)三个方面。
腾讯高级工程师许振文:为游戏分析设计的分布式数据存储系统 腾讯高级工程师许振文带来的演讲题目是《为游戏分析设计的分布式数据存储系统》。他的演讲主要包含腾讯游戏数据分析平台iData、平台后台架构和设计思路以及为游戏分析设计的分布式存储系统三个方面。iData是腾讯互娱运营部-数据中心专注打造的一站式游戏数据服务平台,提供集数据报表、在线分析、用户干预为一体的游戏数据运营服务平台,打造了游戏数据化运营闭环。 
腾讯高级工程师许振文
在数据处理一节,他介绍到,该平台将核心数据与低频数据分离:核心数据经过结构化的预处理,同时采用自研位图分布式存储计算系统做分布式存储计算,提高计算效率,提升分析体验;低频数据适时准备数据,以时间换空间,存储在TDW中。用户按需发起数据调用,通过自研列式存储Bitmap计算引擎实现多维立方体画像、下钻、透视等操作。该平台是一个分布式存储系统,设计为三层架构,最底层主要包括DataNode节点,设计要点包括无元数据管理、可控高效的上传、下载、文件异地补充(MetaNode)、文件check(MetaNode,Client)、数据版本管理和本机状态监控和上报;中间层为MetaNode节点,具有保证元数据的安全和服务的稳定、监控DataNode,异常时告警、定期检查文件,调度DataNode补齐副本数等功能;最上层为MetaNodeMonitor,用于MetaNode运行状态的监控和其角色切换。
最后他向在场的听众介绍了腾讯智营,通过数据分析、挖掘能够进行营销闭环,提供多纬化、智能化的服务。
阿里云技术专家曹龙(封神):Hadoop在云上的最佳实践 阿里云技术专家曹龙(封神)带来的分享是《Hadoop在云上的最佳实践》。阿里从09年开始研究Hadoop,到15年已经具有对外提供Hadoop的能力。云上Hadoop部署架构包括经典部署、存储计算分离、元数据共享、VPC模式以及混合云模式等多种模式,各种模式既可单独使用,又可相互配合使用;同时云上Hadoop具有易用、低成本、深度整合、可靠、安全、专业等优势。 
阿里云技术专家曹龙(封神)
在云上Hadoop的挑战一节,针对由于数据量增大和集群数目的增加导致的Shuffle、本地化、自动化运维方面的挑战,他认为需要从以下几个方面进行考虑:
是否需要扩容;
Hive SQL,可以给SQL评分,给出最优写法;
分析存储,比如:指明是否需要压缩;小文件是否过多,是否需要合并;访问记录分析,是否可以把冷数据归档处理;
分析运行时各种JOB统计信息,如:Job的map时间是否过小,运行时reduce是否数据倾斜,单个job是否有一些参数调整。
演讲最后,他根据不同的场景介绍了多个云上最佳实践案例,如面对需要统计小时以内的各种维度的UV数据,从A页面进入B页面的数据,方便运营同学做更好的营销方案;另外,一些主题小组内的页面排序,希望根据用户的浏览情况自动排序这种场景,最佳实践方案是采用在离线混合的模式。
Hulu大数据架构组负责人董西成:Hadoop YARN在异构环境下应用与实践 本场峰会最后一个登场的讲师是Hulu大数据架构组负责人董西成,他本次分享的主题是《Hadoop YARN在异构环境下应用与实践》。在演讲开始,他首先介绍了异构导致的原因,其主要包括两个方面:首先是机器 ,机器有各种各样的,刚开始时整个集群使同构的,但随着集群的扩大,新加入的机器由于购买时期不同,集群中可能存在多种型号不同(CPU、memory、network、OS,、libraries)的机器,机器上操作系统也有可能不兼容;其次也可能是负载、网络、磁盘IO等动态因素。 
Hulu大数据架构组负责人董西成
随后,他指出,对于静态因素,主要可以通过隔离不同型号的机器,将它们分配给不同的框架,例如分配给Spark的是128GB内存的机器,分配给Spark streaming是 10G-network的机器;而对于动态因素则需要在框架级别解决。
在之后的分享中,董西成详细分享了Label-based scheduling设计,之所以需要Label-based scheduling是因为以下原因:
为不同的Apps分配不同的机器;
由于不同的APP安装特定的库或者服务;
对于一些低延时需求的关键应用更需要进行物理机级别的隔离。
接下来,他有介绍了几种YARN上的框架结构,主要是Nesto(MPP 引擎)和Voidbox(YARN上的Docker)。演讲最后,他介绍了Hulu在YARN实战上的经验。第一个YARN本身作为一个管理系统提供足够丰富的语义让你表达你想表达的意思,同时可以将某些节点添加到黑名单,YARN不会再分配其资源了;第二个是tracking url,包括注册和注销的URL跟踪。同时他提到在不远的将来Voidbox将会作为开源的框架提供给大家。
大数据核心技术与应用实战峰会(下):六专家带你探秘各企业内的大数据实践
2016-07-12 21:18:11 来源:极客头条