每隔三十秒就会有位置数据返回,包括来自于司机和乘客应用的各类数据,需要实时使用的实时数据非常之多,那么Uber是如何存储这些位置数据的呢?
Uber的解决方案非常全面:他们在Mesos顶层构建了自己的系统,运行Cassandra。Uber的软件工程师Abhishek Verma有一个演讲,题为《Uber跨多个数据中心运行在Mesos上的Cassandra》(点击这里查看PPT),便对这个解决方案做了全面的解释。
我们是否也该这么做呢?在聆听Abhishek的演讲时,这样的想法涌入脑海。
如今,开发者有许多艰难的选择要做,我们是否应当将所有的内容放在云端?应该用哪一个云?不会太贵吧?我们是否担心锁定的问题?或者应该兼容并包,精心构思一个混合型框架?还是应当自行解决存储问题,而不使用云端——以免达不到50%的毛利。
Uber决定自行构建,更准确的说法是:他们决定通过融合两个很有用的开源组件,拼合出自己的系统。这样一来,只需要找出办法让Cassandra和Mesos能够协调运作,这也是Uber所做的事情。
对于Uber来说,这个决定并没有太过艰难,他们的财务不是问题,也能够接触到顶尖的人才与资源库,来创建、维护、更新这种类型的复杂系统。
由于Uber的目标是在99.99%的情况下有能力解决任何人在任何地点的交通出行问题,因此,在目标无限广阔的时候,有能力控制开支便很重要了。
不过在聆听演讲时,我们还是会发现制作这类系统所付出的努力有多么惊人。普通的公司能做到这些么?实际上很难。如果你也对云秉持拒绝态度,希望大家都凭空从头建立自己的代码,那么请记得这一点。
通常来说,用金钱换时间是笔不错的交易,用金钱换技术是绝对必要的。
如果Uber的目标是可靠性——请求失败率只有万分之一的话,他们需要许多数据中心。由于使用了Cassandra来处理跨数据中心的大量载入与处理工作,在选择数据库时我们要考虑这一点。
如果想为所有人在任何地方都能提供可靠的交通出行,我们要高效地利用自己的资源,这就是Uber选择Mesos这样的工具作为数据中心OS的原因。通过统计,在同一台机器上使用多路复用服务,可以减少30%的机器以节省开支。而具体选择Mesos的原因在于:在作出选择时,Mesos是唯一能够在上万台机器所构成的集群上运行的产品,而这一点正符合Uber的需求。
其中一些比较有趣的发现包括:
可以在容器中运行有状态服务。Uber发现,这样做几乎没有差别。直接运行Cassandra,与在容器中由Mesos管理着运行Cassandra,其开销相差只有5-10%。
性能十分优秀:读取延迟(13毫秒)和写入延迟(25毫秒)都很低。
在最大的集群上,系统能支持每秒超过100万的写入和约10万的读取吞吐量。
敏捷比性能更加重要。使用这类架构,Uber获得了敏捷性。想要跨集群创建和运行工作负载都非常容易。
下面是本文作者对该演讲的注释:起初针对不同的服务,有不同的静态分区机器。
可能有50台机器专门负责API,50台负责存储等等,彼此工作并不重叠。
现在所有工作都要运行在Mesos上,包括那些有状态的服务,比如Cassandra和Kafka。
Mesos是一个数据中心OS(Data Center OS),允许使用者将数据中心视为单独的资源池来编程。
由于Mesos可运行在数万台机器上,这正是Uber的需求之一,因此他们选择了Mesos,不过如今Kubernetes可能也能达到同样的效果。
Uber在MySQL顶层构建了自己的分片数据库Schemaless。Cassandra和Schemaless就是Uber的两个数据存储选项。已有的Riak实现会被转移到Cassandra之上。
单独的机器可以运行不同类型的服务。
根据统计,在同一台机器上使用多路复用服务能够缩减30%的机器,这是谷歌在Borg上测试得出的发现。
举个例子,如果一个服务占用大量的CPU,而另一个服务占用大量的存储或内存,两个服务就可以高效地运行在同一个服务器上,因此机器的利用率得到提升。
目前Uber拥有大约20个Cassandra集群,并有计划扩展到100个。
敏捷比性能更加重要。我们需要有能力管理这些群组,并以平滑的方式对其执行不同的操作。
为什么在容器中运行Cassandra,而不是在机器上直接运行?
我们要存储数百GB的数据,还想跨多台机器、甚至跨数据中心执行复制。
同时希望在不同的集群之间实现资源和性能隔离。
在一个单独的共享集群上获得所有这些效果是很难的,举个例子,如果创建一个有一千个节点的Cassandra集群,它是无法扩展的,或者不同集群之间也会有性能干扰。
在生产环境中在两个数据中心(美国西部和东海岸)中有大约20个集群负责执行复制。
最初在中国还有4个集群,不过与滴滴合并后,那些集群就关闭了。
两个数据中心有差不多300台机器。
最大的两个集群拥有每秒过100万的写入&约10万读取能力。
这些集群中有一台存储着位置信息——每隔30秒由司机和乘客的客户端发出的位置信息。读取延迟平均为13毫秒,写入延迟为25毫秒。
大多使用LOCAL_QUORUM的一致性级别,也就是高度的一致性。
Mesos后台工具Mesos不考虑机器的CPU、内存和存储。
在编程时,我们面对着不是单独一台机器,而是一个资源池。
线性扩展:可以运行在数万台机器上。
高可用性:使用Zookeeper在可配置数量的副本中选出leader。
可以运行Docker容器或Mesos容器。
可插拔的资源隔离:Linux使用Cgroups内存与CPU隔离器,还有Posix的隔离器,针对不同的OS有不同的隔离机制。
两级调度器:将Mesos代理的资源用于不同的框架中,各个框架在这些资源顶层自行安排任务。
Apache Cassandra后台程序Cassandra十分适合Uber的用例。
可水平扩展:添加新的节点,便可线性地扩展读取和写入吞吐量。
高可用性:针对可调整的一致性级别,系统具有容错性。
低延迟:在同一个数据中心中,延迟可达到毫秒级别。
操作简单:所有集群都属于同质化集群,没有主服务器,在集群中没有特殊的节点。
足够丰富的数据模型:包含列、复合键、计数器、次索引等等。
与开源软件集成良好:Hadoop、Spark、Hive都有能与Cassandra对话的连接器。
Mesosphere + Uber + Cassandra = Dcos-Cassandra-ServiceUber与Mesosphere协作生成了mesosphere/dcos-cassandra-service,这是一个自动化的服务,使得在Mesosphere DC/OS上执行部署和管理非常简单。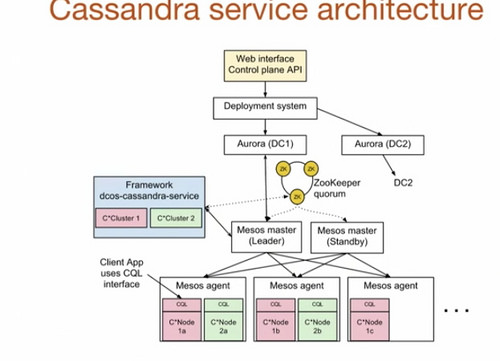
顶层是Web界面或者控制面板API。可以指定想要的节点数量和CPU数量,指定Cassandra配置,然后提交到控制面板API。
Uber的开发系统是在Aurora顶层启动的,用于运行无状态服务,以及引导载入dcos-cassandra-service框架。
在案例中,dcos-cassandra-service框架有两个集群与Mesos主服务器会话。Uber在系统中使用了五个Mesos主服务器,并通过Zookeeper来选出leader。
同时使用Zookeeper来存储框架的元数据,包括:运行哪些任务,Cassandra配置,集群的健康度等等。
在集群的每台机器上都有Mesos代理运行,负责向Mesos的master提供资源,然后master再负责以离散的方式进行分发。框架可以接受或拒绝这些资源,同一台机器上可以运行多个Cassandra节点。
这里使用的是Mesos容器,而不是Docker。
在配置中有5个端口被重写,分别是torage_port、ssl_storage_port、native_transport_port、rpcs_port、jmx_port,这样在同一台机器上就可以运行多个容器了。
由于使用了持久卷,可以将数据存储在沙盒目录的外部。如果Cassandra出错,在持久卷中仍保留有数据,可以提供给刚才崩溃重启的任务使用。
这里使用了动态预留的方式,以确保在重启失败的任务时资源可用。
Cassandra的服务操作
Cassandra有一个概念,就是种子节点的存在。种子节点用于在新节点加入集群时协助进行引导。典型的种子节点提供者会启动Cassandra节点,以便在Mesos集群中自动铺设Cassandra节点。
在Cassandra集群上的节点数量可以通过REST请求来增加。它会开启额外的节点,给它发送种子节点,并引导额外的Cassandra后台程序。
所有Cassandra的配置参数都能修改。
使用API可以替换失效的节点。
在副本间同步数据时需要修复,不过是在以节点为基础的主要键值范围中执行修复,不会影响到性能。
清除程序会移除不需要的数据。如果节点添加成功,数据转移到新节点之后,系统会命令清除程序删除这些冗余数据。
在这个框架中,多个数据中心的副本也是可配置的。
多数据中心支持
每个数据中心都安装有独立的Mesos,以及独立的框架实例。
框架与各个部分对话,并周期性地交换种子节点。
这就是Cassandra所需内容。通过引导其它数据中心的种子,节点会在拓扑中分布,并得出这些节点的内容。
数据中心之间ping的往返延迟为77.8毫秒。
按照第50百分位计算,异步复制延迟为44.69毫秒;按照第95百分位计算,是46.38毫秒;按照第99百分位计算则是47.44毫秒。
调度计划执行
调度计划执行可以总结为计划、阶段和模块。规划好的计划包含不同的阶段,每个阶段包含多个模块。
调度计划的第一阶段就是协调。系统会找出在Mesos之外已经运行的程序。
在部署阶段,系统会检查配置中的节点数是否已经在集群中呈现,并在需要时进行部署。
模块就是Cassandra节点的具体规范。
另外还包含其它阶段:备份阶段、恢复阶段、清理阶段与修复阶段,具体要取决于命中的是哪个REST端点。
集群的开启速度为每分钟一个新节点。
希望每个节点的启动时间达到30秒,
在Cassandra上不能并发启动多个节点。
通常,每个Mesos节点会分配2TB的磁盘空间与128GB的RAM。给每个容器分配100GB,给每个Cassandra进程分配32GB的堆栈。(注意:这个数据可能会有细节错误)。
系统使用CMS来替代G1垃圾回收器,这个垃圾回收器无需任何调优,便可以达到按第99.9百分位计算更为优秀的延迟和性能。
裸机直接运行 VS Mesos管理下的集群使用容器的性能开销如何?裸机代表着Cassandra不运行在容器中。
读取延迟,几乎没有任何区别:5-10%的开销
在裸机中,平均为0.38毫秒,而在Mesos中是0.44毫秒。
按第99百分位计算,裸机是0.91毫秒,而使用Mesos则是0.98毫秒。
读取吞吐量差别很小。
写入延迟。
裸机平均值为0.43毫秒,而使用Mesos平均是0.48毫秒。
按第99百分位计算,裸机是1.05毫秒,使用Mesos则是1.26毫秒。
写入的吞吐量差别也很小。
原文链接: How Uber Manages A Million Writes Per Second Using Mesos And Cassandra Across Multiple Datacenters(译/孙薇 责编/钱曙光)
2016年11月18日-20日,由CSDN重磅打造的年终技术盛会SDCC 2016中国软件开发者大会将在北京举行,大会秉承干货实料(案例)的内容原则,本次大会共设置了12大专题、近百位的演讲嘉宾,并邀请业内顶尖的CTO、架构师和技术专家,与参会嘉宾共同探讨电商架构、高可用架构、编程语言、架构师进阶、微信开发、前端、平台架构演进、基于Spark的大数据系统设计、自动化运维与容器实践、高吞吐数据库系统设计要领、移动视频直播技术等。目前仍是五折抢票,最低1400元,注册参会